A5: Fritter Backend!
30 Nov 2022
Fritter’s first release is finally here! Check out our Minimally Viable Product here!
Abstract Data Models.
App Fritter + Concepts

Individual Concept Schema (with States)

Overall (Connected) Data Model
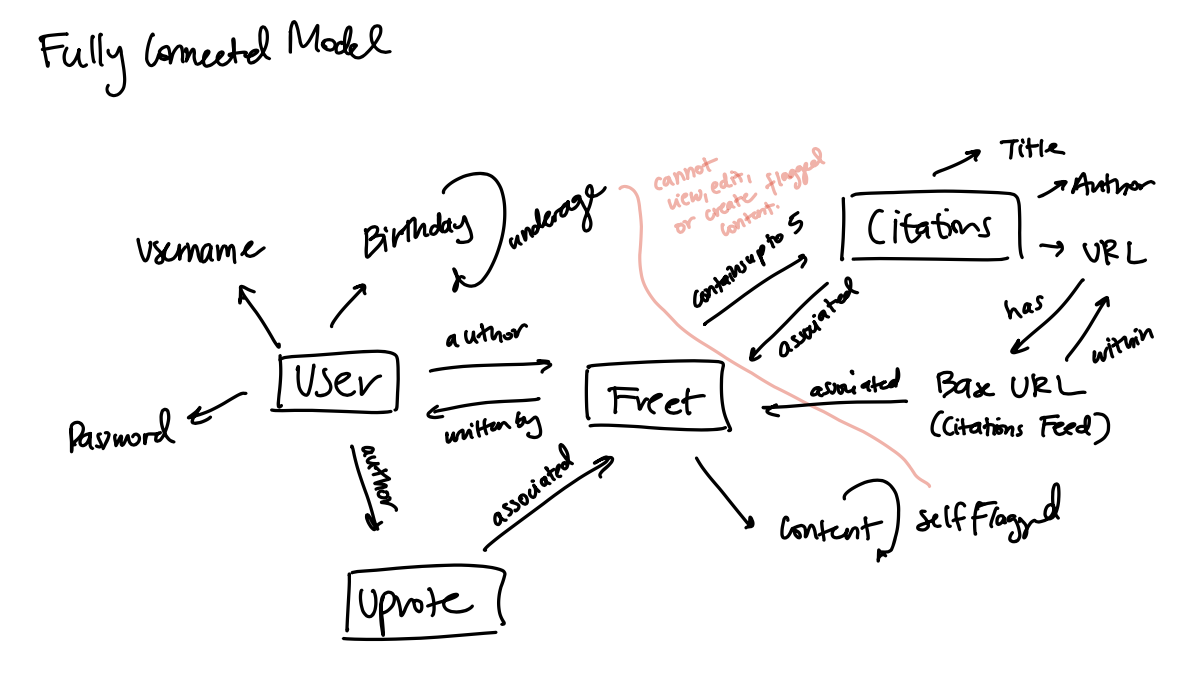
Design Reflection.
For A5 — Fritter Backend, I realized how ambitious I was being even after my A4 Self-Review, as I had eight umbrella conceptual designs. Had I had more time and mental energy, I could’ve followed my ambitions to attempt creating all the concepts. But it was amazing starting out to learn about how deeply we could go into each and every concept – routes and considerations never considered before… and the differences in between, for example, counting how many Freets are currently and actively citing a specific source, versus how many Freets in total are citing those.
A bit about my background — I hadn’t taken 6.031 or developed any backend before, so this assignment broke and blew my mind synchronously. I had many troubles and ambiguities — the ones I mainly stayed stuck on (outside of figuring out what a Schema really is, the Mongoose, TypeScript, and node.js diction) are:
- Should create a stand-alone Schema for some concepts to prioritize modularity? Or do I add concepts to existing Schemas? When talking to Jaeyoon, we resolved these ambiguities by determining that most concepts that contain one-liner information could simply be added onto Schemas for simplicity; if any more information was required, then building a stand-alone Schema for it was probably best.
- Which 5 main concepts should I prioritize? And which should be held off for Phase II of Fritter, after our Minimum Viable Product? I decided on these five:
- User (Adjusted)
- Freet (Adjusted)
- Upvote (Adopted)
- Self-Censorship (Sensitive Content Flag) – where users ages 15-17 could not view flagged posts, or create them
- Citations (Invention)
I was able to implement the first four concepts fully. Unfortunately, I was unable to get to fully implement Citations. I would’ve done so with the above abstract data model, grouping Citations by their base URLs (as suggested by @Gianna before in our A4 peer rreviews), and creating their own Schema. To prioritize synchronocity – and allow users to include Citations within Freets while having their own Schema (for modularity), I would’ve gotten rid of a “POST” RESTful API route within Citations, and create Citations when publishing a Freet with Citations.
- I would’ve done this by having an input form for Citations, just as I have for Freets, and then within the creation of a Freet (within
router.ts), I would’ve ran CitationsCollection.addOne(URL, CitationTitle, CitationAuthor) – with the three parameters being user inputs. - From there, with the creation of Citations, I would’ve added their IDs to the Freet posted by the User.
- From there, I would’ve had to find a way to add Freet IDs back to the citations created.
- I would find the base URL through string modification – so, for example, all NYTimes articles would have the base URL ‘nytimes.com’. And I would’ve created a Citations-based Feed containing all the Freets with citations with the base URL, ‘nytimes.com’!
- What are the best ways to connect concepts to each other? And promote synchronicity?
- For Upvotes, I had a difficult time trying to know how to connect them back to their Users and Freets, in order to prevent Users from upvoting the same Freet multiple times. So, I decided to connect Users to their Upvoted Freets through creating an array inside the User Schema. I manipulate this array of Freet IDs every time the User decides to delete the upvote or the Freet gets deleted. I ommitted continuing on the Downvote principle for A5, as I would have had to find a way to delete Upvotes efficiently by finding the Upvote ID of the existing upvote on the current Freet, by the current User. Resolving dilemmas like these blew my mind.
- A big one – how do I ensure best viewability practices for different groups of users?
- More specifically, how do I ensure that unflagged Freets cannot be created, modified, and viewed by underage users at all? And likewise, how do I store more specific preferences – for now, I display all the flags and their categories, but what if I filtered feeds even by preferences of what flags could be allowed for viewing? I made these filters robust – not even allowing users over “150 years of age” to create an account. But there were so many different checks that I could think of – including making sure that the birthday was input by the user correctly and ensuring that check – as users cannot modify birthdays, and with that check, maybe even disabling certian IP addresses from creating an account for a while if there were multiple attempts to create an account by a potential user who had verified their birthday – and was underage. Why? My friends and I easily created Facebook accounts when we were under the age requirement! As a finesser and lover of loopholes, I wanted to make Fritter as tightly sealed as possible… which leads to another question:
- How do I create robustly, while still creating room for genericity?
- I think this question is similar form of the question about prioritizing modularity – but more so focused on robustness (being in good condition, strong-standing) in terms of addressing unique-to-Fritter policy. I learned my non-negotiables were really in Fritter’s age requirements, as well as navigating them with viewability.
- How do I create for sustainability?
- With the age limits, I thought about what if someone whose
underage: trueboolean would eventually change on their birthday. What if a 17 year old user had their birthday the next day? In a couple of hours? Seconds? Would Fritter keep updated? - When adding and removing attributes to Schemas of concepts, how would they be able to be compatible with older, existing content on Fritter? For example, before creating the concept of a self-Flag, I posted Freets without a Flag principle. How would older Freets be able to function, once all Freets from a certain release date would have new features?
- With the age limits, I thought about what if someone whose
- How would a Freet be connected to its flags? And if Citations had its own concept, should they be grouped by unique URLs? Do users self-input the titles and authors of the URL they’re citing? Or should they be automated through web scraping?
- I decided to allow users to input their own titles and authors of URLs for citing, for now – before rolling in web scraping; and I’ve decided to group citations together by their base URLs. I chose to only allow web-based citations (in the form of URLs) – which would eventually also need a checker – for ease of access. But I’ve realized that even with URLs, addresses can change and become run-down over time. Maybe I would be able to navigate this sustainability issue by regularly checking that links are working through web scraping.
Finally, in order to prioritize preventing: * triggering Fritter users through self-censorship and flagging content, * fueling the spread of misinformation through citations, and finally, * users under 15 years old being on social media platforms (still acknowledging @Chiara’s concerns)…
I’ve decided to rollout the following intended Fritter concepts for a future release after testing out the current MVP:
- Report function,
- Users Self-Flagging themselves,
- Hashtags, and
- Following specific Users for personalized Feed
- Multi-media publishing in Freets (include images)
- Because of the lack of adding images and videos onto Freets, it’s unlikely that users would have any content with “Nudity,” “Violence,” etc., as most self-flagged sensitive content on Twitter is media-based – but I wanted to test the functionality with lower risks anyways.
- I additionally took out the allowance of editing Freets to preserve the authenticity of User and Freet
- If Freets are posted mistakenly, users can delete them; but don’t want to change up on users
- Maybe in the future, if Freets were allowed to be edited in the future, I’d most likely need users to show edit history
What I’ve thought about conceptually highly contrasted from what I was able to actually get done – through A5, I’ve learned a lot of decision-making and prioritizing with due dates, as well as avoiding too much complexity in creating the first Minimally Viable Product for Fritter. Plus, I’ve definitely learned how to take notes to streamline the Backend process. I think, as the 6.1040 staff would know, I would’ve liked to start earlier, but considering the extenuating circumstances this semester, I’m glad I was able to create as much as I’ve had thus far! I learned a lot, and even though meeting this due date has been nerve-racking, I think the pressure actually motivated me to really get started and actively ask for help. I learned better about what questions to ask, and it’s exciting knowing that I could now make simple backend applications! Thanks 6.1040 team, for bearing with me!
Finally, I hope our Fritter users come back with positive and constructive feedback after using our MVP! Enjoy our first release, and let us know what you think!